Hyper-automation, self-driving cars, computer vision applications, and integration of tools are not fiction anymore. Everyone is aware of the AI, ML, and deep learning technologies that are changing the world we live in.
Interest in ML has been increasing for around a decade. Companies are trying to get hands-on ML in most of their upcoming projects.
Are you an organization that has heavily invested in legacy technologies and not want your ML solutions to work on Kubernetes and Dockers?
Open source projects are coming a long way, data scientists prefer heterogeneous unique clusters and algorithms. The python-based tools prove harder while they manage their work across devices or larger organizations.
Every data scientist needs a spinning of the infrastructure. Organizations are aware of groups working on ML and pipeline, enforcing custom pipelines as they couldn’t agree on the existing ones. Many times companies end-up enforcing infrastructure rules to avoid overloading of ML pipelines.
The organizations have previously invested heavily in the technologies like RDBMS, parallel RDBMS, Hadoop, key-value store, spark, but Kubernetes is gaining popularity for managing the on-premises, cloud, and hybrid workload. Since there is always legacy inertia that makes the infrastructure complex, the acceptance of open-source projects in the enterprise in on-premises and on-cloud is slow.
Kubernetes, a container orchestrator that is very essential to data science and microservices applications.
ML learning projects are ready to run on the cloud, but with the inertia of legacy infrastructure and moving towards the latest technology, most companies face obstacles with their data scientists on Ml models. These challenges are broken down into 3 categories.
1) Composability: A machine learning workflow is broken into components that are later arranged in a different formation. Many have their ecosystem and the input one component is used for others.
2) Portability: ML code is rarely portable, run and testing code in different stages of a project like development, staging, production gets tough, and having deltas in the production introduces the production outages.
3) Scalability: Constraints such as the limitation to hardware, network, storage, or heterogeneous hardware lead to a lack of options for scalability.
Dockers or containers are excellent to solve these challenges and Kubernetes is a widely accepted solution to orchestrate and get the best performance from the containers running the algorithms and pipeline.
Managing the cluster of the node to up-scale and downscale entirely depends on Kubernetes. Pods are building blocks of Kubernetes that are distributed for high availability.
Working on dockers makes it easy to enjoy parity in the local, development, testing, staging, production environment. Kubernetes and containers together resolve the issues regarding composability, portability, and scalability especially when we deal with multiple technologies or ML models.
Kubernetes gives many foundational components for ML infrastructure. It scales applications on the cluster and controls the tasks for batch jobs and deployment of long-lived services for model hosting. It also acts as resource manager, where it benefits in,
- Unified management sets a single-cluster management interface for multiple clusters.
- Job isolation makes it easy to move models and extract, transform, and load (ETL) pipelines to production.
- Resilient infrastructure: Manages the nodes in the cluster to provide enough machines and resources.
Though Kubernetes solves the challenges of progressively complex infrastructure, it does not support the ML models and workflows.
Kubeflow:
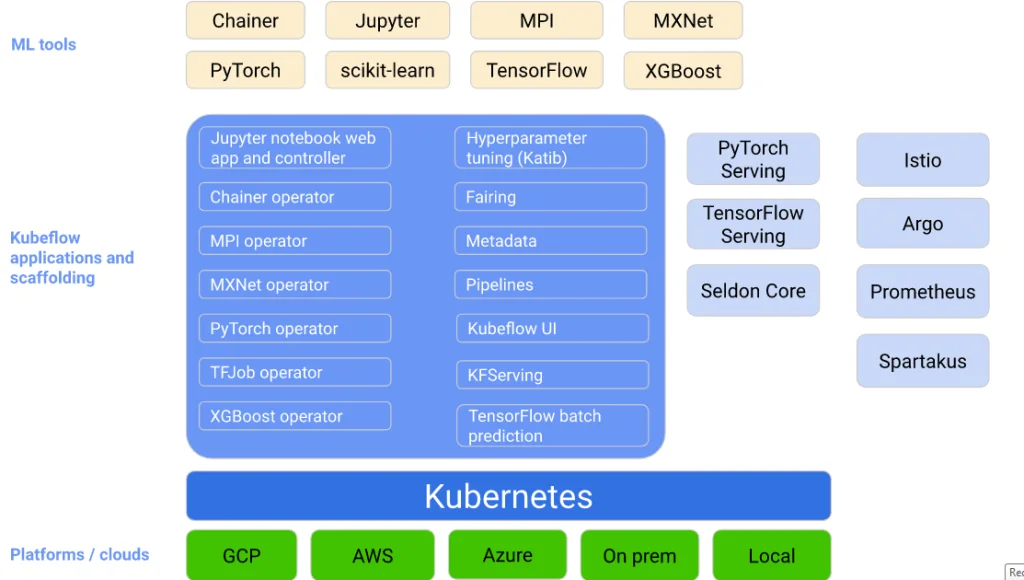
Now the goal is to simply deploy the ML models on Kubernetes. Kubeflow provides a way to run the machine learning workflows on Kubernetes.
Having Kubeflow on Kubernetes, you can,
1) Train and work on ML models in different environments.
2) Models of Tensorflow in Jypyter to manage and train ML jobs.
3) Launching training jobs that require additional CPU’s, GPU’s.
4) Working with different libraries to combine ML models.
A data scientist can use the Kubernetes API directly but this is an extra layer that a data scientist needs to deal with. Initial data models are wrapped into containers and are deployed on the production, this becomes an additional step apart from their ML work. Since data scientists focus on developing, testing, training and deploying the models, it’s best to go with Kubeflow instead of Kubernetes API.
It’s not only for a data scientist but here are different implications of Kubeflow for others:
- Architects and DevOps engineers are responsible for the operational and secure platform of on-premises or cloud, that could support ETL, data warehouse, and modeling efforts of other teams.
- Data engineers used this infrastructure to set the demoralized datasets for ML modeling.
All the teams work on data warehouse and Kubeflow along with Kubernetes provides them with flexibility.
Major Role of Kubeflow:
1)Running on GPUs: GPUs are required to speed up the algebra processing for smaller developers to get the stack on their laptops but fortune 500 companies need a good infrastructure with security along with model integration.
Having Kubeflow makes it easy to build models to explore the concepts of ML modeling.
2) Multitenant environment: Each data scientist can work on their notebooks in the same environment, the KubeFlow and Kubernetes handle these requirements with scheduling and container management functionality.
3) Transfer learning Pipeline: DevOps team keeps track of the access to the sensitive data. While the models are built on the cluster, the multi tenant environment of Kubeflow and Kubernetes helps to achieve the transfer of learning pipelines. Also updating and rolling the model is easy.
KubeFlow is efficient to slow the challenges faced using Kubernetes API during a multitenant environment.
- It implements a faster and consistent deployment strategy.
- Makes it possible to move models in a secure and scalable environment.
- Control the ports and components and manage resources to save costs.
- Rolling and rollouts for the non-completed tasks.
- Orchestration of workflows and collects the metadata for further analysis.
- Enable centralized logging, monitoring, and auditing.
TakeAway:
Kubeflow is best for larger ML projects that require GPUs, multitenant environment for the teams working as DevOps engineer, architects, and data scientist. Working on open source models or libraries is made easy with Kubeflow, Kubernetes, and containers. Having KubeFlow in your environment supports your data scientist to work on models rather than the infrastructure.