

Are your ML models not transforming your real-world problems and delivering values? Or you deal with a large dataset and are not able to manage your IT operations using DevOps?
So MLOps is just for you!
You already have the resources needed for ML solutions. Some are listed below,
- Large datasets to work on Machine Learning models.
- On-demand scalable computing resources.
- AI or ML accelerators to increase the efficiency of ML tasks
- Working models and advancement of ML models by research.
Investing in the ML and data science team is a great idea to work on customized predictive models for a better prospectus of the company
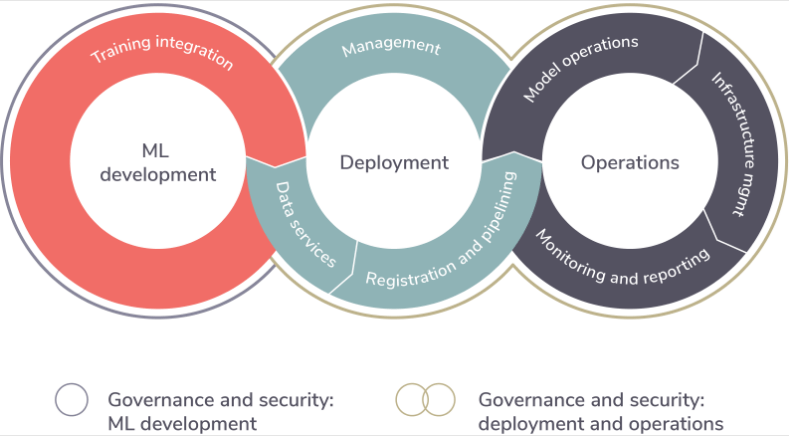
MLOps unifies the ML system development and ML system operation. It automates and monitors the end-to-end steps of ML, starting from development, builds, integration, testing until release and deployment. MLOps also takes care of infrastructure management.
Sustainable ML built by the data scientist using training models holds good for an offline holdout dataset, but the challenge is to create an integrated system that performs on production datasets.
The only solution is to create MLOps that trains your ML model to give better results for unpredicted data from production.
Your systems are already working on DevOps on CI/CD, then why you need to choose MLOps instead of DevOps?
Here is the main difference that makes us understand my we require MLOps over DevOps.
DevOps versus MLOps:
1) Team skills: ML systems work on ML models that are created by data scientists. These scientists focus on model development, parameters, and experiment to train their models. Whereas teams working on DevOps are software engineers that create applications or solutions.
2) Development: Experimenting with various algorithms, modeling techniques, configuration, parameters, and evaluating the quickest solutions is done by data scientists, whereas the DevOps development is more of coding and creating solutions.
3) Testing: ML needs additional testing like the validation of data and models with different configurations and parameters.
4) Deployment: Deployment of the ML systems required skilled professionals to create a multi-step pipeline that automatically retrains and deploys the model. Pipelines automate the manual process done by data scientists during training and modeling.
5) Production: Real-time models deployed in production decay. This may be due to the retraining of models or constantly evolving data profiles. A trigger or constant check is needed to verify if the values deviate from expected values.
Tasks like source control, unit testing, integration testing, data schemas, etc., are common to ML and software projects. But here are additional tasks for ML solutions.
- CI is about testing and validating data, schemas, and models.
- CD is about automated deployment of services
- CT is automatically retraining and serving the models.
Steps for developing ML models:
Once, the ML model is finalized by Data Scientist, these steps are applied for the ML model to deploy in production.
- Data Extraction: It’s the process of selecting and integrating relevant data obtained from multiple data sources.
- Data analysis: Analyzing the data to build the model. This consists of knowing the data schema, data preparation for the selected model.
- Data preparation: Data is vital for ML models. Data is cleaned and split into training data, validation data, and test sets. Sometimes data is transformed to solve the targeted task.
- Model training: Models are trained using clean and appropriate data to get the best results from the ML system. Hyper parameters are also tuned to get the expected results from the models.
- Model Evaluation: Evaluation of model is against the test set, that is acquired from the same datasets. This assures the quality of the model.
- Model Validation: Validating the model against the predictive performance and the baseline performance is essential. If the predictive performance is better than the baseline, the model is accepted for deployment.
- Model Serving: The model is deployed on the target environment. The models work with Microservices using REST API, embedded model, mobile device, or can be used in batch prediction system.
- Model monitoring: Since models deviate and degrade, monitoring of predictive performance is essential to invoke a new iteration in the ML process.
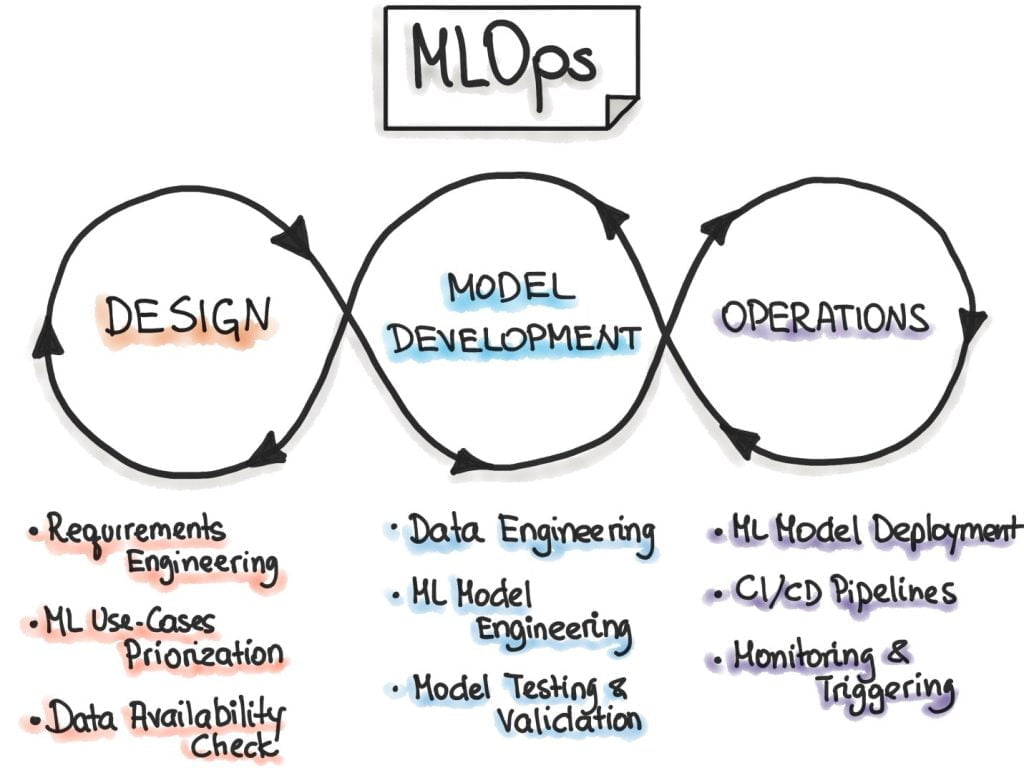
MLOps maturity levels
ML is used to automate the steps required for data analysis. Automated steps in the process mean a mature process that is handling the model by retraining or sustain themselves for new data.
Let’s see the brief description of maturity levels in MLOps systems
- MLOps Level 0: Manual process:
It’s the basic level of maturity. The data scientist and ML researches build models, but building and deployment are manual.
- MLOps Level1: ML Pipeline automation:
MLOps contains ML pipelines involved for the continuous training of models. Continuous delivery of model predictions service includes automated data, model validation steps, and metadata management in the ML pipeline.
- MLOps level2: CD/CI pipeline automation:
By nature ML systems are robust, the automated production pipelines for CI/CD systems explore new features for models, hyperparameters, and architecture. Using pipelines, these features are automated to target the right environment.
Since, we are concern about automating the pipeline, let us know the stages of the pipeline.
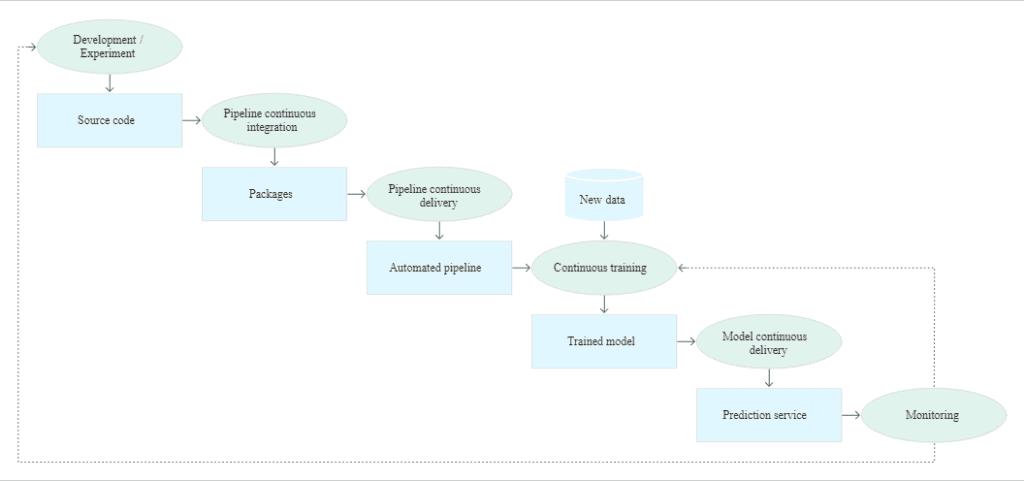
- Development and experimentation: This stage is to try new ML algorithms and models. It decides the steps of the ML pipeline.
- Pipeline continuous integration: Building the source code ML pipeline and running against the various test.
- Pipeline continuous delivery: CI stage produces artifacts to be deployed in the pipeline with a new model for implementation.
- Automated triggering: The trained model is pushed to the model registry by the execution of the pipeline.
- Model continuous delivery: A trained model is used for predictions.
- Monitoring: Model performance is measured, this triggers the execution of pipeline or new experimental cycle.
CI Process:
CI process contains the continuous process of building the pipeline and its components, testing as the code commits itself into the repository.
CD process:
CD delivers a prediction service for the newly trained model as the new pipeline implements in the target environment.
To summarize, having MLOps is an advantage for the company. It is not only about getting models and analysis, but it is about the having CI/CD process implemented in ML systems. For this MLOps implementation using the CI/CD process along with automated pipelines is best.











{kind=link}