As a data scientist, how often do you hear the DAG (Directed Acyclic Graph)? It’s every single day!
DAG is defined as a sequence of computational steps, in complex non-recurring computation. DAG’s are tasks, performing discrete amounts of work. Overall the tasks make up for a larger piece of work like ETL jobs, ML jobs, CI jobs, deployment jobs.
Workflows cover a broad range of use cases. So where do you start when selecting a tool?
There are many tools: Argo, Kubeflow, and the most popular Apache Airflow. These tools are different in terms of their usage and display work on discrete tasks defining an entire workflow.
Initially, all are good for small tasks and team, as the team grows, so as the task and the limitations with a data pipeline increases crumbling and frustrations. Selecting any ML tool is not a solution.
- EC2 instance type reduces
- Increases awkwardness with unknown software.
- Scheduling and retries with increases of custom workarounds.
- Trying of Unknown know not known to the community or lack of knowledge.
Usually, these are the common scenarios for a data scientist as they end up doing a proof-of-concept, to compare the tools.
Why implement MLOps for ML systems?
DevSamurai Vietnam will give you a overview and specified comparison of 4 best Machine Learning platform.
How to choose ML tools?
Six things are essential when you consider the experimental tracking tool.
- Open Source solutions: Should I use an open-source or commercial solution? There are differences between open source and commercial solutions. One obvious difference is, you pay for commercial solutions, and don’t pay for open source. Other relevant considerations are you get the community support for open source solutions, customizations are easily done to avoid lock-in, however commercial solutions have expert support and emphasis on UI/UX and ease of use.
- Platform and Language support: Much of data science is done in Python and few widely adopted frameworks. Most experimental tracking tools offer simplified tracking tools, but if you are using less used languages or frameworks, you face the lack of structured help documents API’s or have no support for some languages.
- Experimental data storage: Experiment tracking tools store experiment data, in the local, cloud, or hybrid ( locally + cloud). Having locally you have the advantage of analyzing it on-fly, whereas having it on the cloud is best for preserving and sharing knowledge. The optimal solution is to have both, but not supported by all tools.
- Custom Visualizations: A key element for different tracking tools is their ability to represents different experiments visually. A good visual representation will enable you to analyze and interrupt results quicker. A right graph can help to communicate results to others. Visualizations are an effective way to show complex data concisely and clearly.
- Ease of step and use: Convenience is an important factor, some tools are powerful and track each data, but difficult to use in data science workflow. Some may have uncomfortable premium UI/UX, where others may have a clean and elegant interface.
- Scalability: Experiment tracking needs to depend on the team and experiment volume. A tool supporting 100 experiments won’t support 100000 experiments. If you plan for larger experiments, it’s important to make sure the chosen tool supports your experiments.
As data science ML code is a small set of code, around it an undifferentiated heavy lifting of infrastructure requirement, scaling, data extraction, tagging, classification, so much time spent on doing the work around it.
Why Machine Learning on Kubernetes?
It’s a great platform, there are 3 requirements for ML,
- Composability: Data tagging, data classification, data ingestion, having training, inference, are potentially different microservices. Kubernetes is orchestrating microservices, and building your entire machines learning platform.
- Portability: As you are running these infrastructures, you want to make sure these are portable, you are working on mobile, desktop, or tab you want an environment, which works across these different compute environments, across different clouds.
- Kubernetes gives you the basic compute layer working across the different computing environments.
- Scalability: As you try to add GPU’s, inference, infrastructure, and scaling, Kubernetes scales the clusters, adds more capacity, and more workloads at it.
So you run big clusters and machine running code on top. So these three reasons why Kubernetes is suitable for machine learning.
As a data scientist, you figure the model, the location of model storage, UI, what tools and frameworks to be used, is the app used is the right version for the computing environment.
As a data scientist, you are going to imaging the unique combination as you work on your laptop, on the training rig, and in production up in the cloud. This is where KubeFlow is needed.
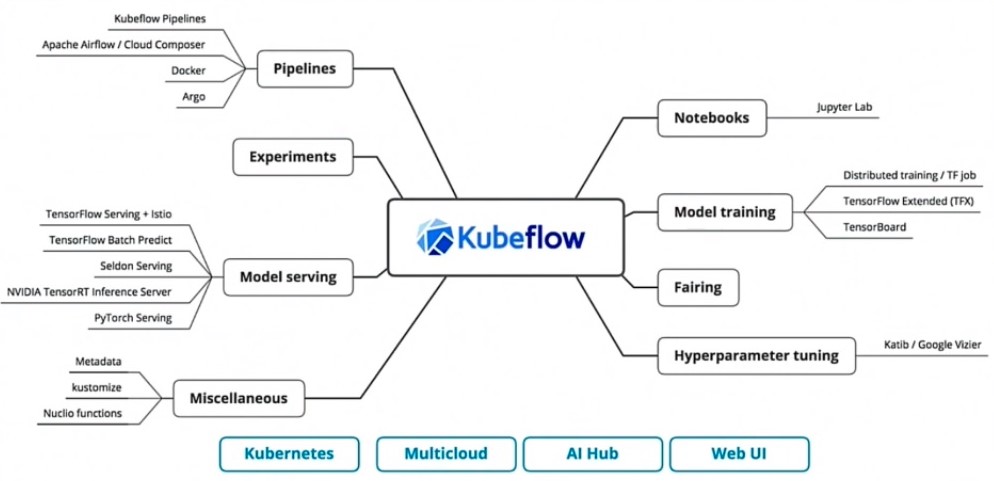
KubeFlow
KubeFlow: Work on ML workloads with Kubernetes
Kubeflow builds on the Kubernetes giving an abstraction, an easy way to develop, deploy and map, help to manage the Kubernetes platform.
Kubeflow: is a containerized machine learning platform working to easy to develop, deploy, and manage portable, scalable, end-to-end workflows on k8s.
“Toolkit”, loosely coupled, tools and blueprints, for ML.
Data scientists used frameworks like PyTorch or TensorFlow, CRD for training, but you require models to spread on multiple nodes. Model training is CRD, which is installed as part of Kubeflow install.
Model serving: Fairing python SDK, Training code, convert it into a docker image, convert into Kubernetes image and deploy it. This gives control to data scientists to install into production.
Hyperparameters tunning, learning rate, number of layers in CNN networks identify how efficiently your model will run. Identify an optimal set of parameters, all these toolsets come as part of Kubeflow and simplifies ML experience on Kubernetes.

Airflow
Its python-based orchestration platform for operation teams has the best UI to display the workflow. Extending the workflows to 10000 scalings is best to handle and is popular to date.
Started by Airbnb, it has vibrant community support and up to 500 active members.
- DAG’s: DAG’s are easy to create, with Airflow 2.0, now uses PythonOperators, special attention is given for XCom and dependencies.
- Rest API: It’s the highlight of AirFlow, AIP-32 is supporting full REST API, that uses the OpenAPI specifications.
- Scheduler: Schedular in Airflow is significantly faster due to horizontal scalability. Achieved through high availability, scalability, performance, runs multiple schedulers concurrently.
- Install in Packages: Airflow now comes with 60+ packages, so the possibility of custom airflow increases with available packages or required packages.
Widely used, a fully customized and consistent runtime is the main highlight of airflow.
MLFLow
Finding a standardized machine-learning platform is a daunting task. Offen the custom ML platforms like Facebook FBlearner, Uber Michelangelo, Google TFX have some of the standardized ML platforms but limited with few algorithms. Tied to companies infrastructure a single data scientist can’t use these.
MLFlow is an open-source platform for ML lifecycle, built on an open framework philosophy. It finds several abstractions that integrate the existing algorithms and infrastructure for ML easily.
The open integrated platform gives a way to use the existing framework and algorithms to integrated into the ML platform.
- It works with any machine learning library.
- Easily reproducible. Same ML code is designed to run on several environments, like cloud, local machine, or notebook.
- Legible, good for small teams, as well as a large organization, have 1000s of ML practitioners.
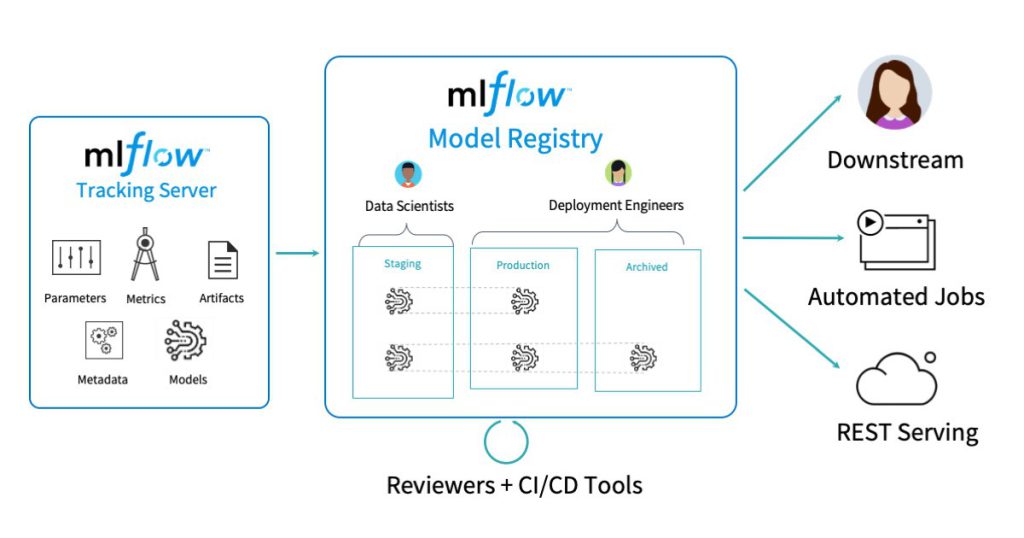
- Focuses on tracking, projects, and models. Tracks central databases for storage of metadata. Projects are reproducible self-containing packaging format model that runs the same regardless of the execution environment. Model format, to support diverse deployment tools.
Focusing on the key concepts like parameters, metrics, source, version, artifacts, tags, and notes. it stores data in any location. It consists of a tracking API that uses REST, Python, JAVA, or R. This information is aggregated by a centralized tracking server. It has a pluggable designed to run on variety and popular infrastructure.
Argo:
Continuous deployment and scaling with infrastructure and services is challenging for any R&D team. This can be done only by automation, visualizations on the support of the cloud along with containers. For jobs, a scalable hooper manages software development lifecycle, workflow like CI/CD, testing, experimentation, deployments.
A container-native workflow engine feeds and manages the Kubernetes workflow, it schedules and coordinates the run of workflows.
It combines a workflow engine, with native artifacts management, admission control, fixtures, built-in docker-in-docker policies, etc. Mainly used for,
- Traditional CI/CD pipelines.
- Jobs with sequence and parallel steps dependencies.
- Orchestrating deployments of complex, distributed applications.
- Policies to enable time/event-based execution of workflows
Each step is implemented using containers, It provides simple, flexible mechanisms for specifying constraints between the steps in a workflow and artifact management for linking the output of any step as an input to subsequent steps. Integrating artifact management with workflows is critical for achieving portability as well as for greater efficiency and simplicity. By building workflow steps entirely from containers, the workflow itself including all execution of steps as well as interactions between steps are specified and managed like source code.
Another advantage of an integrated container-native workflow management system is that workflows can be defined and managed as code (YAML). With Argo, workflows are not only portable but are also version-controlled. A workflow that runs on one Argo system will run the same on another Argo system. Just point your new Argo system to the same source repo and container repository as used by your previous system.
Takeaway:
While selecting the right ML platform, it’s easy for data scientists to get confused with the pros and cons offered by the platform. This article explains the criteria to select the ML for your projects also we have discussed the top ML frameworks that are used widely by industry.
DevSamurai Vietnam is partner of Google Cloud, Sonatype, Atlassian and silver member of CNCF, the LINUX Foundation. With strengths of Cloud Computing, DevOps, Kubernetes, we support client to drive their project and business transformation to success by cutting edge technology, high-leveled skill and worthy price. Contact DevSamurai Vietnam for more information or to start a project now.