
Bộ nhớ là một thành phần quan trọng của bất kỳ cơ sở hạ tầng nào dựa trên đám mây. Nếu không có nơi để lưu trữ và cung cấp dữ liệu của bạn, cơ sở dữ liệu sẽ không hoạt động, máy tính không thể chạy và mạng sẽ không có nơi nào để gửi dữ liệu đang mang theo. Bộ nhớ là một trong ba chi phí đám mây hàng đầu đối với nhiều khách hàng, và nhu cầu lưu trữ của hầu hết các công ty chỉ tăng lên mà không có giảm. Không có gì đáng ngạc nhiên khi nhiều người đặt câu hỏi về cách để tối ưu hóa chi phí lưu trữ của họ.
Phần lớn các môi trường lưu trữ đám mây sử dụng lưu trữ đối tượng (object storage), trái ngược với lưu trữ tệp (file) hoặc khối (block) được sử dụng trong hầu hết các môi trường tại chỗ. Bộ nhớ đối tượng của Google Cloud – Cloud Storage là một lựa chọn vô cùng phù hợp để lưu trữ hàng loạt lượng dữ liệu lớn. Lưu trữ đối tượng vốn không có cấu trúc (các cặp khóa – giá trị, với các giá trị là rất lớn), nhưng các tệp được lưu trữ bên trong có thể là dữ liệu nhị phân, dữ liệu văn bản hoặc thậm chí là các dịnh dạng dữ liệu chuyên biệt như Apache Parquet hoặc Avro.
Lưu trữ đối tượng là giải pháp rẻ nhất và có khả năng mở rộng cao nhất dành cho phần lớn dữ liệu của bạn. Song dù giá cả của lưu trữ đối tượng thấp, chi phí lưu trữ vẫn có thể tăng lên. Đối với một tổ chức có nhiều khối lượng công việc đang chạy và nhu cầu thay đổi theo thời gian, việc tối ưu hóa nhu cầu lưu trữ đám mây (và chi phí) cho mỗi ứng dụng mới được di chuyển có thể trở thành một thách thức.
Bạn có thể lưu dữ liệu trên bộ nhớ đám mây theo nhiều cách. Cách của bạn sẽ phụ thuộc vào một loạt các yếu tố, bao gồm nhu cầu vòng đời dữ liệu, các mẫu truy xuất, yêu cầu quản trị và hơn thế nữa. Chúng ta hãy cùng tìm hiểu cách tiết kiệm cho bộ nhớ đối tượng trong Google Cloud, bằng cách tập trung vào hai quyết định lớn nhất mà bạn có thể đưa ra – các vùng trên Google Cloud nơi bạn lưu trữ dữ liệu và các tùy chọn lớp lưu trữ mà bạn có thể lựa chọn.
Bắt đầu với cấu hình phù hợp
Cơ hội đầu tiên của bạn để tiết kiệm bộ nhớ đối tượng là khi bạn cấu hình bucket ban đầu. Việc thiết lập bộ nhớ rất dễ dàng, nhưng có một số quyết định quan trọng bạn cần thực hiện. Một số lựa chọn, chẳng hạn như vị trí lưu trữ, sẽ trở nên khó khăn và tốn thời gian để thay đổi khi lượng dữ liệu bạn đang lưu trữ tăng lên. Vì vậy, điều quan trọng là phải đưa ra một quyết định phù hợp với nhu cầu của bạn.
Vùng
Lựa chọn vùng lưu trữ cũng chính là công việc cân bằng giữa chi phí, hiệu suất và tính khả dụng. Chi phí lưu trữ Regional (đơn vùng) là thấp nhất và cao hơn là các cấu hình dual-region (vùng kép) hoặc Multi-region (đa vùng).
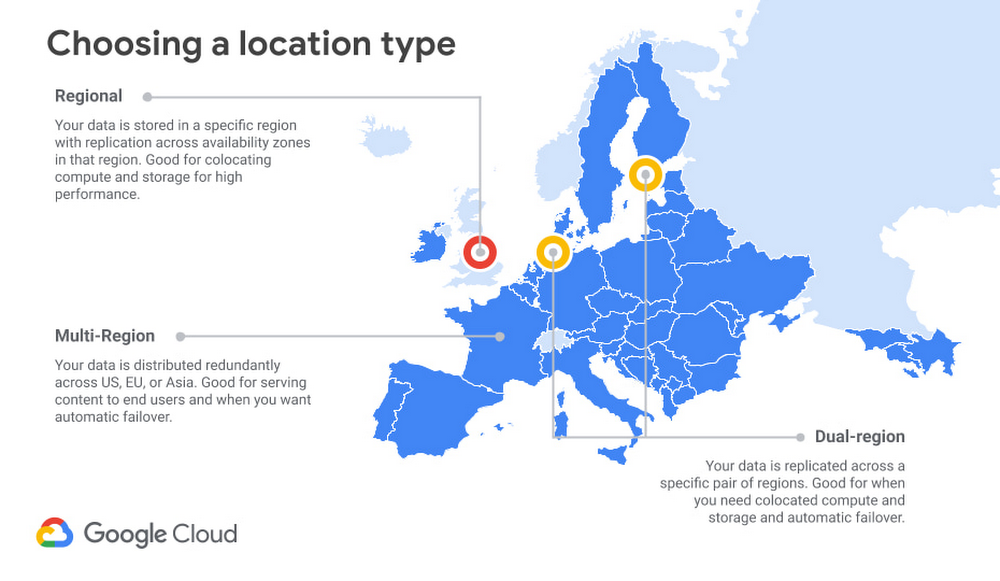
Nhìn chung, lưu trữ đơn vùng có tính khả dụng thấp nhất. Đúng như tên gọi, nó bị giới hạn ở một khu vực duy nhất. Tuy nhiên, dữ liệu vẫn còn rất khả dụng. Với cách lưu trữ trên một vùng duy nhất, dữ liệu được lưu trữ dự phòng trên nhiều khu vực (zone) trong vùng (tìm hiểu thêm về Google Cloud regions and zones tại đây). Hệ thống của Google Cloud được thiết kế để cô lập các lỗi trong một zone.
Lưu trữ vùng kép và đa vùng cung cấp tính khả dụng cao hơn, vì hiện nay có nhiều vùng (với nhiều khu vực trong mỗi vùng) có thể phục vụ các yêu cầu, cung cấp quyền truy cập vào dữ liệu ngay cả khi xảy ra sự cố ngoài ý muốn trên toàn vùng.
Về mặt hiệu suất, việc lựa chọn một vị trí cho bộ nhớ của bạn là một vấn đề phức tạp. Nhìn chung, việc đặt dữ liệu của bạn vào một vùng (bằng cách lựa chọn lưu trữ đơn vùng hoặc vùng kép) sẽ giúp tăng hiệu suất đáng kể khi người đọc và ghi dữ liệu ở cùng một vùng. Ví dụ, nếu khối lượng công việc của bạn được lưu trữ trong một vùng của Google Cloud, bạn có thể muốn đảm bảo rằng bộ nhớ đối tượng của mình được đặt trong cùng một vùng để giảm thiểu số lần nhảy mạng, hay nói cách khác là giảm thiểu số lượng thiết bị chuyển mạng cần đi qua. Còn nếu khối lượng công việc tại chỗ sử dụng Cloud Storage để đọc và ghi, bạn có thể muốn sử dụng kết nối liên vùng chuyên dụng để giảm thiểu mức tiêu thụ băng thông tổng thể và cải thiện hiệu suất.
Ngược lại, lưu trữ đa vùng thường sẽ mang lại hiệu suất tốt khi cần phục vụ trực tiếp lưu lượng truy cập đến một khu vực địa lý rất lớn, chẳng hạn như Châu Âu hoặc Bắc Mỹ, có thể sử dụng hoặc không sử dụng Cloud CDN. Nhiều ứng dụng, đặc biệt là ứng dụng dành cho người tiêu dùng, sẽ cần tính đến độ trễ dặm cuối cùng giữa khu vực đám mây và người dùng cuối. Trong những tình huống này, các kiến trúc sư có thể tìm thấy nhiều giá trị hơn ở lưu trữ đa vùng, vì nó mang lại tính khả dụng rất cao và tiết kiệm chi phí hơn so với lưu trữ vùng kép.
Xét về chi phí, lưu trữ đơn vùng là lựa chọn có giá thấp nhất. Vùng kép là đắt nhất, vì bản chất của chúng là hai nhóm vùng với siêu dữ liệu được chia sẻ, cùng với tính năng lưu vị trí của người tham gia (attendant) và hiệu suất cao. Đa vùng có mức giá trung bình, vì Google có thể lưu trữ dữ liệu tiết kiệm hơn bằng cách duy trì sự linh hoạt trong việc lựa chọn vị trí lưu dữ liệu. Thông thường, với mỗi 1$ dành cho lưu trữ đơn vùng, bạn sẽ phải trả khoảng 1.3$ cho đa vùng và khoảng 2$ cho vùng kép với bất kỳ lựa chọn lớp lưu trữ nào.
Vì có sự khác biệt đáng kể về hệ số, điều quan trọng là bạn cần suy nghĩ một cách chiến lược về vị trí cho bucket của mình. Mặc định, một số dịch vụ tạo nhiều bucket ở các vùng của Hoa Kỳ, nhưng đừng chấp nhận mặc định một cách mù quáng. Hãy xem xét các yêu cầu về hiệu suất và tính khả dụng của bạn, đồng thời đừng trả tiền cho sự dư thừa địa lý và tính khả dụng nhiều hơn mức bạn cần.
Lớp lưu trữ
Sau khi đã lựa chọn vị trí cho bucket của mình trên Cloud Storage, bạn cần chọn tiếp lớp lưu trữ mặc định. Google Cloud cung cấp 4 lớp: Standard (tiêu chuẩn), Nearline (gần tuyến), Coldline (đường lạnh), và Archive (lưu trữ). Mỗi lớp là lựa chọn lý tưởng cho các cấu hình truy xuất dữ liệu khác nhau và lớp mặc định sẽ tự động được áp dụng cho tất cả các lần ghi mà không được chỉ định lớp. Để có độ chính xác cao hơn, lớp lưu trữ có thể được định nghĩa trên từng đối tượng riêng lẻ trong bucket. Ở cấp độ đối tượng, lớp lưu trữ có thể được thay đổi bằng các ghi lại đối tượng hoặc sử dụng Quản lý Vòng đời Đối tượng (Object Lifecycle Management).
Mức giá lưu trữ được tính theo nhu cầu sử dụng, tuy nhiên vẫn có một “hợp đồng” ngầm trong giá cả để giúp bạn có được thỏa thuận tốt nhất cho trường hợp sử dụng của mình. Trong trường hợp lưu trữ nóng hoặc tiêu chuẩn, hợp đồng có giá lưu trữ hàng tháng trên mỗi GB cao hơn nhưng không yêu cầu phí bổ sung trên mỗi GB cho việc truy xuất hoặc xóa sớm. Đối với các lớp lưu trữ nguội hơn, chi phí lưu trữ mỗi GB hàng tháng có thể sẽ thấp hơn nhiều nhưng bạn phải xem xét chi phít trên mỗi GB khi truy xuất hoặc xóa sớm. Mục tiêu của bạn chính là chọn ra một lớp lưu trữ mặc định sẽ tạo ra tổng chi phí thấp nhất cho trường hợp sử dụng của bạn trong hầu hết thời gian. Một cái nhìn dài hạn (hoặc dự báo) đóng vai trò rất quan trọng.
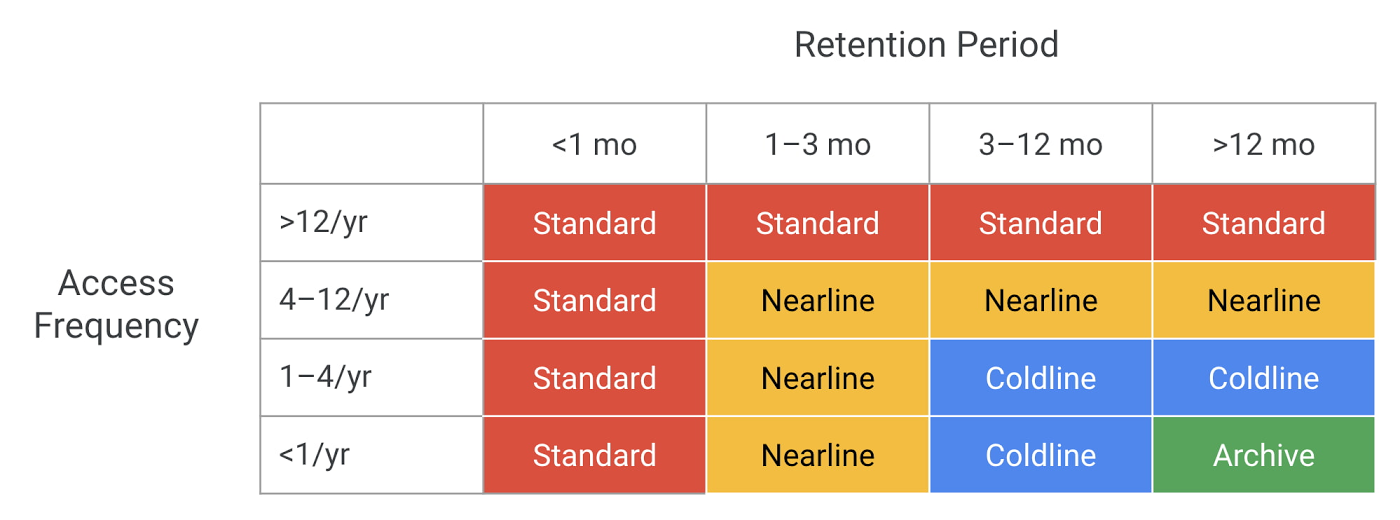
Google đã đặt ra các nguyên tắc về mỗi lớp như sau.
- Standard: Truy cập thường xuyên, không có yêu cầu về thời gian lưu trữ dữ liệu tối thiểu. Đây là dữ liệu nóng.
- Nearline: Truy cập ít hơn một lần mỗi tháng, lưu trữ hơn một tháng.
- Coldline: Truy cập ít hơn một lần mỗi quý, lưu trữ hơn một quý.
- Archive: Truy cập ít hơn một lần mỗi năm, lưu trữ hơn một năm.
Tuy nhiên, điều gì sẽ xảy ra nếu quyền truy cập vào dữ liệu trong các lần truy xuất là khác nhau? Nhiều người dùng Cloud Storage lưu trữ dữ liệu trong hơn một năm (hoặc vô thời hạn), vì vậy chúng ta sẽ đơn giản hóa vấn đề bằng cách không phân tích chi phí xóa sớm. Giả sử rằng bạn sẽ giữ lại tất cả dữ liệu của mình trên Cloud Storage trong hơn một năm. Tuy nhiên, đối với chi phí truy xuất, nếu bạn có một trường hợp giới hạn – một hỗn hợp các trường hợp mà bạn không thể dễ dàng dự đoán hoặc chỉ để có được kết quả chính xác hơn, bạn có thể sử dụng công thức sau để tìm điểm hòa vốn cho tần suất truy cập giữa hai lớp lưu trữ.
Đặt:
hs = Chi phí lưu trữ hàng tháng theo Gigabyte cho lớp nóng hơn
cs = Chi phí lưu trữ hàng tháng theo Gigabyte cho lớp lạnh hơn
cr = Chi phí truy xuất theo Gigabyte cho lớp lạnh hơn
Thì:
(hs - cs) / cr = Phần dữ liệu được đọc mỗi tháng tại điểm hòa vốn
Lấy ví dụ, xem xét bộ nhớ Standard với Nearline Regional ở us-central1 (với mức giá của tháng Một năm 2021):
(0.02GB/tháng - 0.01GB/tháng) / 0.01GB = 1.0/tháng = 100% mỗi tháng
Điều này có nghĩa rằng bạn có thể đọc tới 100% lượng dữ liệu bạn lưu trữ trong Nearline một lần mỗi tháng và vẫn hòa vốn. Tuy nhiên, hãy ghi nhớ hai lưu ý đối với cách tính này:
- Số lần đọc lại cũng được tính. Việc đọc đi đọc lại 1% dữ liệu của mình 100 lần trong tháng cũng giống như đọc 100% dữ liệu trong một lần.
- Tính toán này giả định kích thước đối tượng trung bình lớn (hàng chục MB hoặc hơn). Nếu bạn có các tệp rất nhỏ, chi phí hoạt động sẽ ảnh hưởng đến kết quả tính.
Tuy nhiên, nếu bạn đang đọc ít hơn 100% dung lượng bạn đã lưu trữ và không có các đối tượng nhỏ (như biểu đồ bên dưới), bạn có thể tiết kiệm chi phí chỉ bằng cách sử dụng bộ nhớ Nearline.
Hãy xem biểu đồ dưới đây để có được cái nhìn trực quan về xu hướng này trên tất cả các lớp dữ liệu. Đây là biểu đồ biểu thị chi phí lưu trữ và duy trì cho các lớp lưu trữ đơn vùng của us-central1. Các xu hướng này sẽ giống nhau ở tất cả các cách lựa chọn vị trí lưu trữ, chỉ có điểm uốn Tỷ lệ tốt nhất là khác nhau.
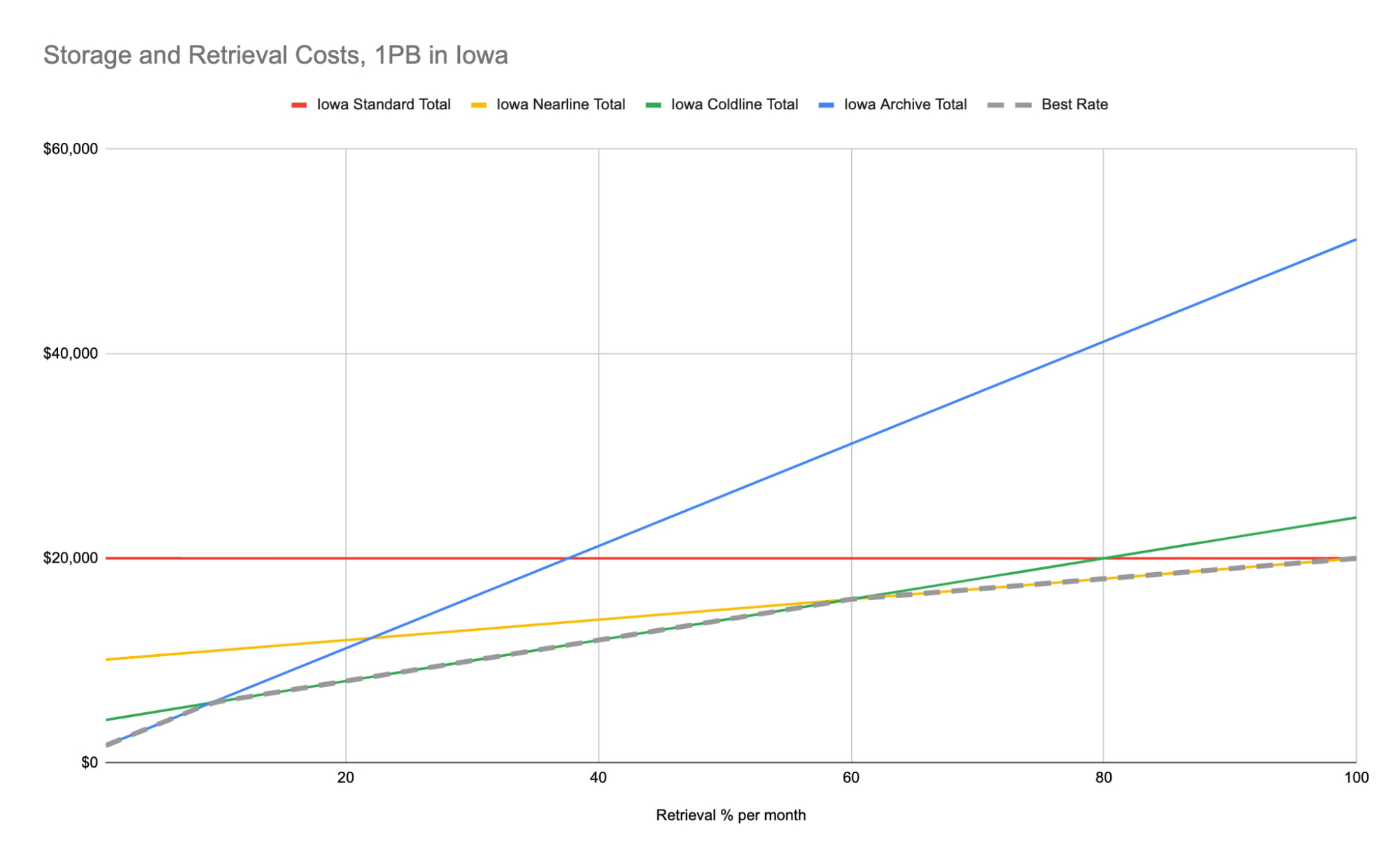
Một lần nữa, giả sử rằng bạn định lưu trữ dữ liệu của mình trong một năm hoặc lâu hơn, và bạn muốn lựa chọn lớp lưu trữ tuân theo đường chấm Tỷ lệ tốt nhất được hiển thị ở trên. Trong trường hợp này, các điểm uốn cho dữ liệu được đọc chính xác một lần mỗi tháng lần lượt là khoảng 10%, 60% và 100% cho Archive, Coldline và Nearline.
Một cách hiểu khác về biểu đồ này chính là, nếu bạn truy cập ít hơn 10% dữ liệu của mình hoặc ít hơn chính xác một lần mỗi tháng, Archive là lựa chọn hiệu quả nhất về chi phí dành cho bạn. Nếu bạn truy cập từ 10% đến 60% dữ liệu của mình chính xác một lần mỗi tháng, Coldline là lựa chọn tối ưu hóa chi phí. Và nếu bạn muốn truy cập từ 60% đến 100% dữ liệu của mình chính xác một lần mỗi tháng, thì Nearline là lớp lưu trữ có chi phí thấp nhất. Bộ nhớ Standard sẽ là lựa chọn tốt khi bạn cần truy cập 100% dữ liệu của mình hoặc nhiều hơn chính xác một lần mỗi tháng – điều này khiến nó trở thành một lựa chọn tốt nếu bạn thường xuyên truy cập dữ liệu với nhiều lần đọc đi đọc lại.
Kết luận
Lưu trữ đối tượng đóng một vai trò quan trọng trong các ứng dụng đám mây và các doanh nghiệp có dấu chân lưu trữ đám mây lớn phải theo dõi chi phí lưu trữ cho đối tượng của họ. Dịch vụ lưu trữ đối tượng của Google – Cloud Sotrage cung cấp nhiều tùy chọn khác nhau để giúp khách hàng tối ưu hóa chi phí lưu trữ của họ.
Trong bài đăng này, chúng tôi đã chia sẻ một số hướng dẫn về hai cách quan trọng nhất để thực hiện tối ưu hóa chi phí: lựa chọn vị trí lưu trữ và lớp lưu trữ. Vị trí lưu trữ và lớp lưu trữ được xác định khi bucket của bạn được tạo và mỗi tùy chọn cung cấp những sự cân bằng khác nhau. Những hướng dẫn ở trên được thiết kế để giúp bạn đưa ra lựa chọn phù hợp nhất với nhu cầu lưu trữ của mình. Bạn có thể tìm hiểu thêm thông tin về Cloud Storage trong các hướng dẫn how-to của Google.
Theo Google Cloud Blog


















