

Việc xây dựng các pipeline end-to-end ngày càng trở nên quan trọng khi nhiều doanh nghiệp nhận ra rằng việc có một mô hình máy học chỉ là một bước nhỏ để phát triển ứng dụng máy học của họ. Google Cloud cung cấp một công cụ để huấn luyện và triển khai các mô hình trên quy mô lớn – Cloud AI Platform, được tích hợp với nhiều công cụ điều phối như TensorFlow Extended hay KubeFlow Pipelines. Tuy nhiên, các doanh nghiệp thường có các mô hình mà họ đã xây dựng trong hệ sinh thái của riêng họ, sử dụng các framework như scikit-learn và xgboost. Việc di chuyển các mô hình này lên đám mây có thể rất phức tạp và tốn thời gian.
Ngay cả đối với những người có kinh nghiệm làm việc trên Google Cloud Platform, việc di chuyển một mô hình scikit-learn (hoặc các mô hình tương đương) sang AI Platform có thể đòi hỏi nhiều thời gian do vấn đề ở các boilerplate (bảng tạo sẵn). ML Pipeline Generator là một công cụ cho phép người dùng dễ dàng triển khai các mô hình máy học hiện có trên GCP, nơi họ có thể hưởng lợi từ việc huấn luyện và triển khai mô hình không máy chủ (serverless) và tiết kiệm thời gian hoàn thành giải pháp của họ.
Tổng quan
ML Pipeline Generator cho phép người dùng có các mô hình scikit-learn, xgboost và TensorFlow có thể nhanh chóng tạo ra và thực thi một đường ống ML end-to-end trên GCP bằng cách sử dụng mã nguồn và dữ liệu của riêng họ.
Để thực hiện công việc này, người dùng phải cấu hình mô tả siêu dữ liệu mã nguồn của họ. Thư viện sẽ đọc những cấu hình này và tạo tất cả các boilerplate cần thiết để người dùng huấn luyện và triển khai mô hình của họ trên đám mây, và điều phối bằng cách sử dụng công cụ tạo template. Hơn nữa, những người dùng huấn luyện mô hình TensorFlow có thể sử dụng tính năng Explainable AI để hiểu rõ hơn về mô hình của họ.
Hình dưới đây thể hiện kiến trúc của đường ống được khởi tạo. Người dùng sẽ mang theo dữ liệu của riêng họ, xác định cách thức tiền xử lý dữ liệu và thêm vào các file ML của họ. Sau khi người dùng hoàn thiện file cấu hình, họ sẽ sử dụng một API python đơn giản để tạo ra các boilerplate độc lập, tải dữ liệu của họ lên Google Cloud Storage (GCS) và khởi chạy các công việc huấn luyện của họ sau khi điều chỉnh siêu tham số (hyperparameter). Sau khi những công đoạn này hoàn thành, mô hình sẽ được triển khai, và tùy thuộc loại mô hình, những giải thích về mô hình sẽ được cung cấp. Toàn bộ quá trình này có thể được điều phối bằng Kubeflow Pipelines.
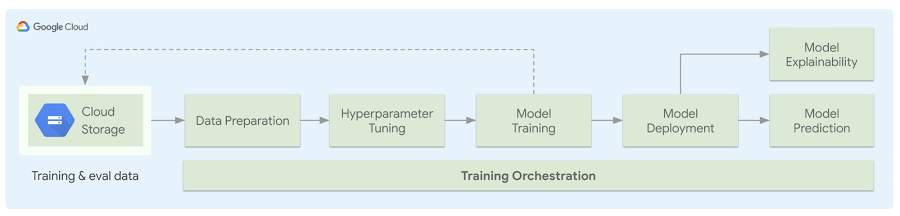
Các bước thực hiện
Dưới đây là cách bạn có thể xây dựng pipeline Kubeflow end-to-end để huấn luyện và cung cấp một mô hình, dựa trên các tham số cấu hình mô hình và mã nguồn mô hình. Chúng ta sẽ xây dựng một pipeline để huấn luyện mô hình TensorFlow đơn giản trên tập dữ liệu Census Income. Mô hình sẽ được huấn luyện trên Cloud AI Platform và có thể được giám sát trong giao diện người dùng Kubeflow.
Trước khi bắt đầu
Để đảm bảo rằng bạn có thể sử dụng giải pháp một cách đầy đủ, bạn cần thiết lập một số mục trên GCP:
1. Bạn cần một Google Cloud project để chạy bản demo này. Bạn nên tạo một project mới và đảo bảo các API sau đã được khởi động:
– Compute Engine
– AI Platform Training and Prediction
– Cloud Storage
2. Cài đặt Google Cloud SDK để có thể truy cập các dịch vụ GCP được yêu cầu thông qua command line. Sau khi SDK được cài đặt, hãy thiết lập credentials mặc định cho ứng dụng với ID của project bạn vừa tạo ở trên.
gcloud auth logingcloud auth application-default logingcloud config set project [PROJECT_ID]
3. Nếu bạn đang tìm cách triển khai mô hình máy học của mình trên Kubeflow Pipelines bằng giải pháp này, hãy tạo một đối tượng (instancce) KFP mới trên AI Platform Pipelines trong project của bạn. Hãy ghi lại hostname của đối tượng (Dashboard URL có dạng [vm-hash]-dot-[zone].pipelines.googleusercontent.com).
4. Cuối cùng là tạo một bucket để lưu trữ dữ liệu và các mô hình trên GCS. Hãy nhớ ghi lại ID của bucket.
Bước 1: Thiết lập môi trường
Hãy clone repo này để lấy mã nguồn demo và tạo môi trường ảo Python.
git clone https://github.com/GoogleCloudPlatform/ml-pipeline-generator-python.git cd ml-pipeline-generator-python python3 -m venv venv source ./venv/bin/activate
Cài đặt package ml-pipeline-gen.
pip install ml-pipeline-gen
1. Thư mục examples/ chứa mã nguồn mẫu cho mô hình sklearn, TensorFlow và XGBoost. examples/kfp/model/tf_model.py sẽ được sử dụng để triển khai mô hình TensorFlow trên Kubeflow Pipelines. Tuy nhiên, nếu bạn đang sử dụng mô hình của riêng mình, bạn có thể sửa đổi file tf_model bằng mã nguồn mô hình của mình.
2. File examples/kfp/model/census_preprocess.py tải xuống tập dữ liệu Census Income và thực hiện tiền xử lý cho mô hình. Đối với mô hình tùy chỉnh của bạn, bạn có thể tùy ý thay đổi mã nguồn tiền xử lý cho phù hợp.
3. Công cụ này phụ thuộc vào file config.yaml cho siêu dữ liệu cần thiết để xây dựng các tạo tác (artifacts) cho pipeline. Mở template examples/kfp/config.yaml.example để xem các thông số siêu dữ liệu mẫu, và bạn có thể tìm thấy giản đồ chi tiết tại đây.
4. Nếu bạn đang muốn sử dụng tính năng điều chỉnh siêu thông số (hyperparameter tuning) của Cloud AI Platform, bạn có thể đưa các thông số vào một file có tên hptune_config.yaml và thêm đường dẫn của nó vào config.yaml. Bạn có thể xem lược đồ cho hptune_config.yaml tại đây.
Bước 2: Thiết lập các thông số cần thiết
1. Tạo một bản sao của thư mục kfp/ example
cp -r examples/kfp kfp-demo cd kfp-demo
2. Sử dụng template config.yaml.example để tạo file config.yaml. Cập nhật các tham số với project ID, bucket ID, KFP hostname bạn đã ghi chú trước đó và tên của mô hình.
project_id: PROJECT_ID bucket_id: BUCKET_ID data: train: “gs://BUCKET_ID/MODEL_NAME/data/adult.data.csv” evaluation:"gs://BUCKET_ID/MODEL_NAME/data/adult.test.csv" prediction: input_data_paths: - "gs://BUCKET_ID/MODEL_NAME/inputs/*" orchestration : host: “KUBEFLOW_PIPELINE_HOST_URL”
Bước 3: Xây dựng đường ống và huấn luyện mô hình
Với các thông số cấu hình đã có, bạn đã sẵn sàng để tạo ra các module sẽ xây dựng các pipeline để huấn luyện mô hình TensorFlow. Hãy chạy file demo.py.
python demo.py
Trong lần đầu tiên bạn chạy demo Kubeflow Pipelines, công cụ sẽ cung cấp Workload Identity cho cluster CKE – thứ sẽ thay đổi dashboard URL. Để triển khai mô hình của bạn, chỉ cần cập nhật URL trong config.yaml và chạy lại bản demo.
Mã nguồn trong file demo.py sẽ tải xuống tập dữ liệu từ một public Cloud Storage bucket, chuẩn bị tập dữ liệu để huấn luyện và đánh giá mô hình bằng examples/kfp/model/census_preprocess.py, tải tập dữ liệu lên Cloud Storage URL được chỉ định trong file config.yaml, xây dựng đồ thị pipeline để huấn luyện và tải đồ thị này lên ứng dụng Kubeflow Pipelines.
Khi đồ thị đã được submit để thực thi, bạn có thể theo dõi tiến trình của quá trình trong giao diện Kubeflow Pipelines. Hãy mở trang Cloud AI Platform Pipelines và Dashboard cho Kubeflow Pipelines cluster của bạn.
Lưu ý: Nếu bạn muốn sử dụng các mô hình Scikit-learn hoặc XGBoost, bạn có thể làm theo các bước tương tự ở trên, thay đổi examples/sklearn/config.yaml với các thay đổi tương tự như thên mà không cần thêm bước tạo đối tượng Kubeflow Pipelines. Để biết thêm chi tiết, hãy tham khảo hướng dẫn trong repo công khai này hoặc làm theo hướng dẫn từ đầu đến cuối của Google Cloud được viết trong một Jupyter notebook.
Kết luận
Trên đây là cách di chuyển mô hình máy học tùy chỉnh của bạn để huấn luyện và triển khai trên Google Cloud trong 3 bước đơn giản. Hầu hết các công việc khó khăn sẽ được thực hiện tự động bởi giải pháp, người dùng chỉ cần đưa dữ liệu của họ, định nghĩa mô hình và cấu hình cách họ muốn huấn luyện, triển khai mô hình.
Để tìm hiểu thêm về Kubeflow Pipelines và các tính năng của nó, hãy xem session liên quan từ Google Cloud Next ‘19.
Nguồn: Google Cloud Blog


















